
Pranav Manoj
Founding Engineer

Eitan Borgnia
Co-founder, COO
A year ago today, we released our first Fast Apply model publicly. Since then, we’ve learned a lot about how to fine-tune small, specialized models for code-specific tasks.
Today, we’re open-sourcing what we've learned in training this series of models — dataset curation, training methods, and inference techniques that led to Relace Apply 3, our best model yet, capable of running at 10k+ tokens per second while maintaining state-of-the-art accuracy.

Figure 1: Error rate comparison on 500 randomly sampled production merge requests. For breakdown of error categories, see section on evaluating merges.
The Problem
When making edits to a codebase, it doesn't make sense to have an expensive LLM regenerate all the unchanged, preexisting code.
Editing a thousand line file (~10k tokens) by rewriting it from scratch with Claude 4.5 Sonnet takes over 100 seconds and costs at least $0.18. For coding agents, this is infeasible from a product perspective.
The solution is to have the frontier model output a diff that minimally expresses the changes to make (i.e. the hard tokens), and use a lightweight algorithm to efficiently apply the diff back into the preexisting code. Not only does this save on cost, but if the merging algorithm is fast, you also significantly speed up end-to-end generation time.
For a long time, LLMs were incapable of reliably producing diff formats that were mergeable by a fixed algorithm like string replace or UDiff.
Cursor pioneered a flexible workaround to this problem — let the frontier model produce "lazy" diffs and use a small, fast apply model as the merging algorithm. However, Cursor never made their model available for other companies to use outside of the IDE.
We decided to train our own apply model that anyone could use.
Why Use an LLM as the Merge Algorithm?
In practice, frontier models can produce a wide variety of pathological diffs. Any closed-form algorithm you write to perform the merge will be susceptible to edge cases. In agentic settings, where there is often no human oversight, these errors compound and produce incorrect code.

Figure 2: Example of a pathological initial_code, diff pair that is hard to address with a closed-form merging algorithm.
In the code above, the user starts with a function called handler. The intent of the diff on the right is to rename the handler function to messageHandler and add a parameter for the name column in the database query.
It would be difficult to write an algorithm that anticipates these two steps. A standard merging algorithm would likely just add a new function called messageHandler, duplicating the original function.
The advantage of using an LLM as the merge algorithm is that it can flexibly infer the intent of the diff. Pretraining on trillions of code tokens bakes in pattern recognition robust to the many edge cases you see in production.
Also, by splitting the task into two steps — diff generation and merge — you can use a much smaller, fast model to focus entirely on the merge. This separation of work based on difficulty is a pattern we exploit a lot at Relace to improve overall performance of coding agents.
To achieve good results without needing to pretrain a model, we fine tune off-the-shelf small models on a high quality dataset that matches the distribution in production.
Producing the Dataset
A training set for fast apply contains three components: initial_code, diff, and merged_code. The initial code and diff are passed in as model inputs, and the merged code is the output we train the model to produce.
For fine tuning, you need a small set of high quality examples. We found the size of the dataset to be much less important than the diversity and quality of merge data. Our first model was trained with only 30k data points, and we saw marginal gains beyond 100k data points.
Inputs
Early on, Kortix AI released an open-source dataset by post-processing data scraped from public GitHub repos. Given some initial code, they prompt a frontier model like Claude to (1) come up with a change to make and (2) produce the "lazy" diff for it.
This turns out to be the wrong approach, as it doesn't reflect the actual distribution of data in production environments. The rich variety of edge cases in diffs comes from context overload. The LLM must adhere to instructions in long system prompts while simultaneously inferring intent from noisy conversations with non-technical users.
To get high-quality, complex merges with plenty of edge cases into the training set, we partnered with prompt-to-app companies. We took snapshots of the real context for LLM coding tasks and reran them with additional instructions to produce the "lazy" edits. This allowed us to sample directly from the true distribution of initial_code and diff that would be seen in production.
Output
To generate the correct merged_code, we use distillation with rejection sampling. The idea is to feed the initial code and diff into a well-prompted frontier “teacher” model, guided by a set of rules for how merges should be handled.
This approach lets you produce a large amount of candidate data quickly, but it’s crucial to filter out the teacher’s mistakes. When done correctly, the trained student model can actually end up outperforming the teacher.
However, filtering correctly is hard. We developed a multi-stage process to build a high quality LLM-as-a-judge that could scale up to thousands of datapoints.
Evaluating Merges
We began by manually reviewing 500 randomly sampled examples to create a set of ironclad ground truths. For our first Apply model, these datapoints were fully synthetic, but we later repeated the process using real production data from earlier iterations of the hosted model.
To streamline the process while maintaining quality, we built our own internal evaluation tool: a Git-style diff viewer with annotation tools for categorizing merge outcomes.
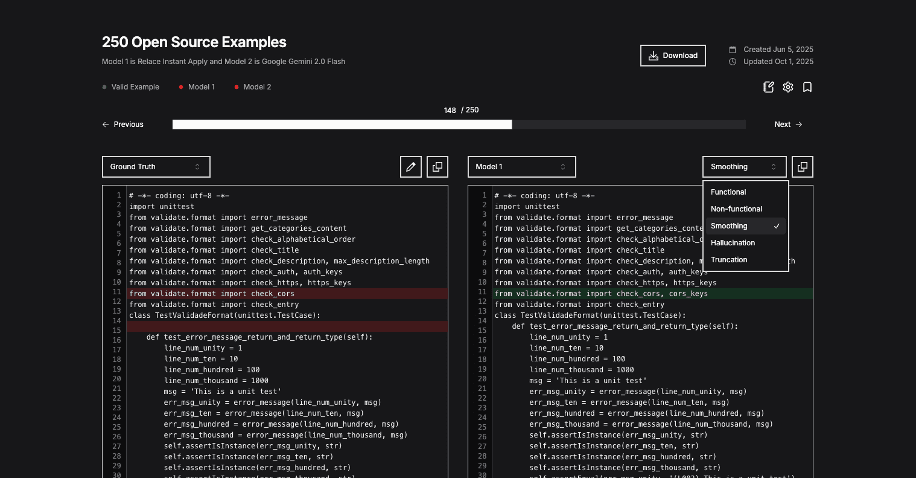
Figure 3: A screenshot of Relace's internal merge evaluation tool.
Even with this tool, it took us over 40 hours to painstakingly ensure 100% correctness. Patterns started to emerge in the process, and we broke down merges into 6 categories:
Correct Merge: Model correctly implemented the intent of the diff.
Non-functional Error: Model implemented the intent of the diff except for inconsequential details such as variation in comments and formatting (e.g. function definitions in different orders).
Smoothing: Model fixed an error incorporated by the diff that would have resulted in uncompilable or broken code.
Functional/Merge Error: Model did not carry out the intent of the diff (e.g. omitting parts of code and inserting code in incorrect places).
Hallucination Error: Model added or changed code not specified by the diff (may be unsuccessful attempts at smoothing).
Truncation Errors: Model performed an incomplete merge (with parts of final code cut out) leading to uncompilable code.
Note: Categories 1-3 are considered correct merges, while 4-6 are considered incorrect. We keep the six-class system for more nuanced evaluations, but collapse to a binary classification when creating the LLM judge.
Aside on Smoothing
We often found that frontier LLMs produced diffs leading to slightly incorrect code. The most common example is when the diff uses a new library in the code without actually importing it.
This raised a question: should a fast apply model strictly follow the diff, or fix the error? In practice, we found customers building coding agents prefer that the model auto-corrects small mistakes to reduce friction for end users.
The hallucination category accounts for cases where the apply model overstepped and introduced more incorrect code to try and fix errors.
LLM-as-a-Judge
Once we had this set of 500 categorized merge examples we could trust, the next step was to align an LLM-as-a-judge to our human-annotated seed dataset. It would be completely infeasible to hand-evaluate enough code merges to create the full training dataset of 100k+ examples.
The LLM-as-a-judge technique exploits the generation/verification gap. i.e. It's easier for an LLM to evaluate whether an answer is correct than to actually generate the answer. Still, the LLM often makes mistakes, and it's important to align it properly with a human evaluation first.
As with any binary classification task, there are two error modes:
False positive - a bad merge is incorrectly classified as good.
False negative - a good merge is incorrectly classified as bad.
Since we have a large synthetic dataset, false positives are the more problematic error mode. It's much worse for bad merges to remain in the dataset than to reduce dataset yield by throwing away a few false negatives.
We used Claude 4 Sonnet as the judge and iteratively tuned the prompt until we hit a false positive rate of ~1%. For comparison, the initial naive judge with no tuning had a false positive rate of ~16%!
Scaling Up
With the aligned LLM judge, it's possible to filter the rest of the data at scale.
For Relace Apply 3, we started with 200k sets of initial_code, diff, and synthetically generated merged_code. We chose a representative distribution of examples across dozens of languages, but focused predominantly on TypeScript/Javascript, Markdown, Python, Ruby, and HTML.
To further cut down on mistakes, we added an extra post-processing step using a combination of static analysis tools — syntax verification with a code parser, deduplication, and regex-based filtering for common undesirable behaviors identified through customer feedback.
After all the filtering, we were left with a high-confidence training set of ~145k data points.
Training with LoRA
For small models, we've consistently found that data quality is the most important ingredient. With a clean, in-distribution dataset, the training just boils down to specializing a high quality base model for the merging task without catastrophic forgetting on general coding.
We trained our apply models using Supervised Fine-Tuning (SFT) on top of open-source coding models in the 3–8 billion parameter range. This gave us the right balance of expressiveness, inference speed, and cost efficiency.
We built our own training pipeline on top of the HuggingFace transformers library, but you can also just use out-of-the-box libraries like axolotl or unsloth.
Since post-training typically uses much smaller datasets than pretraining, updating every parameter in the model is wasteful. Instead of retraining all billions of weights, we use Low-rank adaptation (LoRA) — a lightweight fine-tuning method that adds a small number of trainable “adapter” matrices on top of the frozen base model.
This lets us specialize the model for merge tasks without erasing its coding intuition. The base model stays intact, while the adapters learn the merging algorithm we care about.
We ran a series of grid searches to tune the adapter size (rank), scaling factor (alpha), and learning rate, and landed on the configuration below, which produced the best evaluation loss and convergence speed.
LoRA Rank | LoRA alpha | Learning Rate | Optimizer |
|---|---|---|---|
128 | 32 | 5e-5 | AdamW |
Interestingly, we independently validated the optimal hyperparameters for LoRA published in the recent Thinking Machines blog post.
Using LoRA allowed us to train Relace Apply 3 on all ~145k data points using a single Nvidia H200 GPU on Modal with context length up to 64k tokens.
Using Modal allowed us to launch parallel training runs on H200 GPUs without having to wrestle with complicated cloud providers. Even though small model training lets you get way with batch size 1 on a single GPU, running a large hyperparameter sweep would normally take a lot of manual setup. With Modal, we ran our Python scripts and let it handle the scaling for us — no need to ssh to new GPU instances every time.
After training in BF16, we convert the model weights to FP8 using the llm-compressor library from vLLM. This conversion step is crucial — by leveraging the FP8 cores on newer Nvidia GPUs, we achieve a substantial jump in throughput without sacrificing precision.
To confirm that the quantization process was effectively lossless, we evaluated the resulting model against our 500 held-out ground-truth examples to validate that the outputs were the same.
10k tok/s with Speculative Decoding
With the model trained, our goal was to make it feel less like a slow language model and more like a closed-form algorithm for merging code. To reach that user expereince, we needed to push inference speed as far as possible — which meant turning to speculative decoding.
LLMs normally generate tokens sequentially, where each new token depends on the ones that came before it. This dependency makes inference inherently slow, since every step requires a full forward pass through the model.
Speculative decoding takes advantage of the fact that forward passes are heavily memory bound. i.e. Shuttling the LLM weights into the GPU sRAM takes much longer than actually performing the matrix multiplication with the tensor cores. By guessing a sequence of k tokens, we can process many tokens in parallel (like prefill) and move more towards to the compute-bound regime.
After the forward pass, the model checks which of the predicted tokens match the "true" next tokens and keeps the ones that are correct. The better the "guess", the more tokens you accept, and the more you accelerate the model.
For code merging, large sections of the initial_code and diff are nearly identical to what appears in the merged_code. We can use this strong prior to get long, high quality guesses for what tokens the model should output and get huge speed ups.
However, speed and accuracy are tightly coupled for speculative decoding. Each hallucinated token interrupts the guessed sequence, resetting the verification chain and wasting computation.
By training on the meticulously cleaned dataset, we minimized these breaks and were able to push Relace Apply 3 to 10k tok/s:

Figure 4: Distribution of Relace Apply 3 throughput speed after first token (measured in tokens/second)
Results
We tested Relace Apply on two datasets: (1) our manually reviewed benchmark of 500 examples, and (2) a second dataset of pathological merges collected from customer feedback.
Across both, Relace Apply 3 achieves state-of-the-art merge accuracy. Substantial improvements were made over the previous generation of Apply models thanks to targetted dataset tuning based on customer feedback.

Figure 5: Comparison of merge accuracy between Relace Apply 2 and Relace Apply 3 on a dataset of pathological merge requests.
Previous generations of fast apply struggled when edit snippets contained multiple diff formats in one (e.g. combining \\ ... existing code ... format with UDiff edits). We included subsets of UDiff and String Replace edits in the training data for Relace Apply 3 allowing it to act as a universal merger.
Relace Apply 3 also introduces native support for 256k context, allowing it to handle very large files without degradation in performance. Combined with the 10k tok/s throughput, this makes Relace Apply 3 the fastest, most accurate, and longest-context model on the market.
Fast Apply, One Year Later
When we released our first Fast Apply model a year ago, LLMs were notoriously bad at outputting valid diff formats. Deterministic approaches like Search-and-Replace or UDiff were brittle, model-specific, and required extensive prompt engineering.
Diff formatting accuracy became such a bottleneck that Aider’s polyglot leaderboard tracked it as a separate metric — one column for accuracy, another for performance.
Fast Apply changed that. It was the first model to make structured code edits feel reliable, and our customers felt the difference immediately.
Today, frontier models have become much better at diff formatting through heavy reinforcement learning on string-edit tools, but they’re still not perfect. Companies that exclusively use deterministic strategies, like Cline, need a supplementary merge algorithm to help further boost the diff edit accuracy.

Figure 6: Schematic reconstructed from an X post by the Cline team. Even deterministic approaches require fallback logic to handle edge cases.
The best models now reach roughly 96% edit success, but models without this kind of tuning still fail around 10% of the time.
So while we expect that, over time, apply models may be phased out as diff accuracy improves, the underlying philosophy that drove it remains central to new projects.
Fast Apply proved that small, specialized models can deliver SoTA results when trained with high quality, task-specific datasets. The methods we developed are now guiding our broader work on accelerating codegen with small agentic models for utility tasks like search, merge conflict resolution, and refactoring.
Stay tuned for more releases soon!
We're Hiring
If you have gotten this far, chances are you found this interesting!
We’re hiring pragmatic researchers (Physics/Math/CS/ML) and exceptional engineers to ship models like this that real product teams rely on. Check out our careers page, and join us!